
Why PureLogic?
Pure domain logic
A well-known software architecture principle is to separate pure domain logic from side effects. The idea is simple: your core business rules (e.g. validation, calculations, state transitions) should be pure functions that take inputs and return outputs, without performing I/O, accessing databases, or calling external services. Side effects are pushed to the boundaries of your application.
This separation has significant benefits:
- Reasoning: You can understand what a pure function does by reading its signature and body. There are no hidden interactions with the outside world.
- Testability: Pure functions are trivial to test. No mocks, no test containers, no setup/teardown: just input and output.
- Reusability: Pure domain logic can be reused across different contexts (HTTP handler, CLI, batch job, test) without modification.
- Refactoring: Changing how you interact with a database or an API does not require changing your business rules.
This is sometimes called the Functional Core, Imperative Shell pattern.
Of course, not every application fits this model perfectly. If your domain logic is inherently interleaved with I/O (e.g. a proxy, a streaming pipeline), there is less to gain. But for many applications (especially those with rich business rules, such as financial systems or games), this separation pays off quickly.
PureLogic is designed for this pure core. It gives you a small set of capabilities (Reader, Writer, State, Abort) that let you express common patterns in domain logic (accessing configuration, accumulating logs or events, managing state, handling errors) without introducing side effects.
Direct style vs monads
In the Scala ecosystem, the traditional approach to pure functional programming relies on monads (types like ZPure or ReaderWriterStateT) that are composed using flatMap and for-comprehensions. While powerful, this approach comes with trade-offs that PureLogic avoids by using direct style instead.
Simpler code
With monads, every effectful operation must be sequenced using flatMap or for-comprehensions. Compare:
// Monadic style (ZPure)
ZPure
.foreachDiscard(0 until n) { _ =>
for {
r <- ZPure.service[Int, Int]
s <- ZPure.get[Int]
next = s + r + 1
_ <- ZPure.set(next)
_ <- ZPure.log(next)
} yield ()
}
.flatMap(_ => ZPure.get[Int])
// Direct style (PureLogic)
(0 until n).foreach { _ =>
val next = get + read + 1
set(next)
write(next)
}
getThe direct-style version is plain Scala. There are no for-comprehensions, no <-, no yield, no type ascriptions needed to help the compiler. You use val, if, while, for, and all the standard control flow you already know.
This simplicity compounds as your code grows:
- No
traverse/sequence: You want to map over a list and perform an effect for each element? Just use a regularforeachormap: no need fortraverseor its variants. - Better type inference: Monadic code often requires explicit type annotations to help the compiler, especially with monad transformers. Direct style rarely does.
- Lower learning curve: New team members don't need to learn monad transformers, type class hierarchies, or the intricacies of
flatMapcomposition.
Trade-offs
There are two trade-offs to be aware of when choosing direct style over monads:
- Referential transparency: Direct-style code that uses capabilities is not referentially transparent: you cannot freely reorder or deduplicate expressions. My personal opinion is that it won't matter much in practice for this kind of pure logic code.
- Trampolining: Effect systems typically use trampolining (converting recursion into heap-allocated steps that are interpreted in a loop), so deeply recursive monadic programs won't overflow the stack. With direct style, you need to make recursive functions
@tailrecor restructure them to avoid deep recursion.
Performance
Because PureLogic operations compile down to simple reads and writes on mutable variables behind the scenes (safely scoped by Logic.run), there is no overhead from monadic wrapping, flatMap chains, or heap-allocated closures.
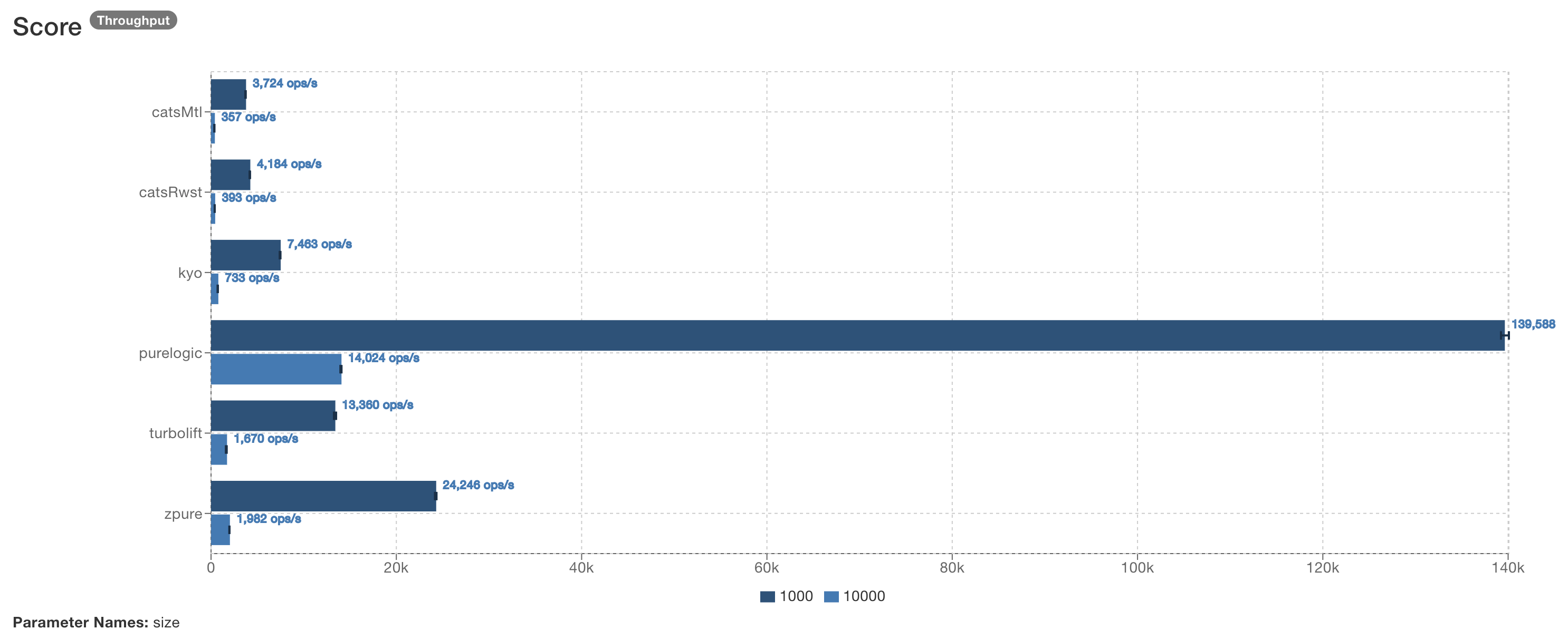
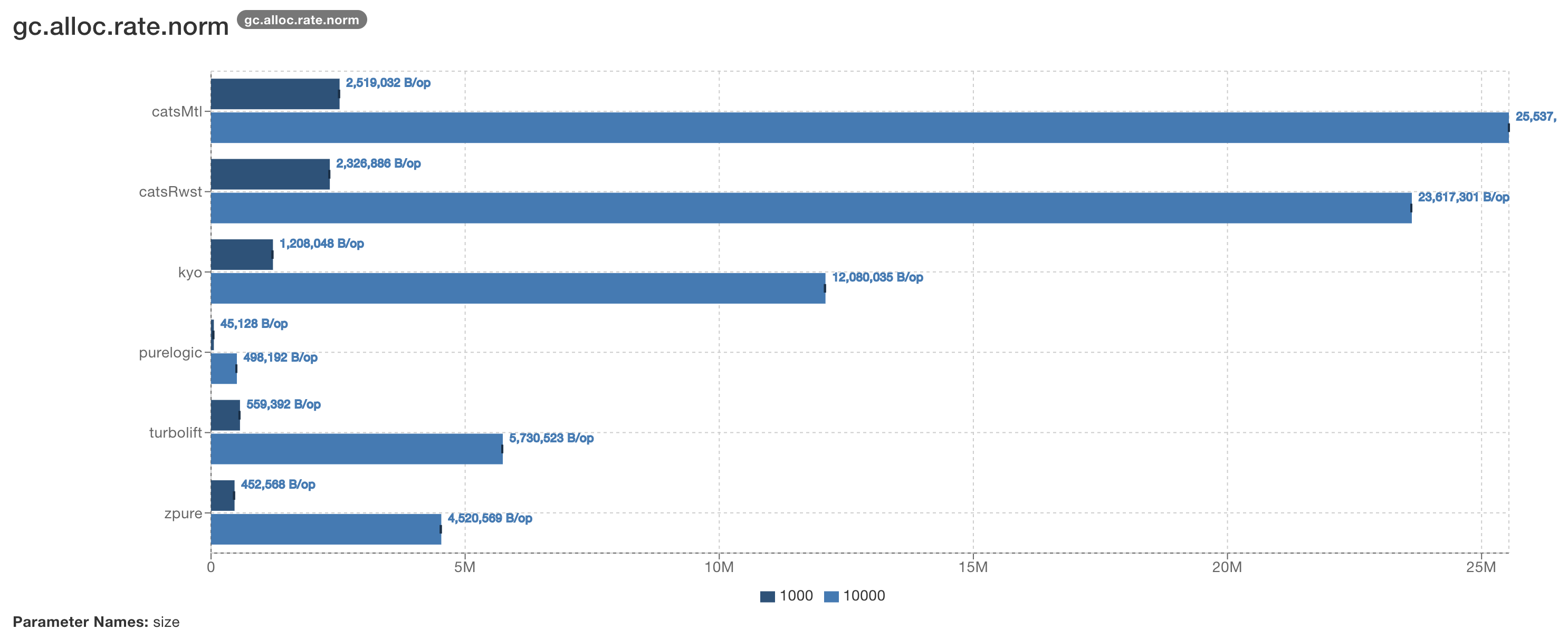
JMH benchmarks comparing PureLogic to other Scala libraries that offer similar capabilities (Reader + Writer + State + Error) show that PureLogic is 7-40x faster and allocates 10-50x less memory depending on the library and workload size. This is a direct consequence of the direct-style approach: there is no monadic overhead to pay.
Better stack traces, profiling, and debugging
Monadic programs are notoriously difficult to debug. Stack traces are filled with flatMap, map, and internal interpreter frames, making it hard to find where the actual error occurred. Profilers and debuggers suffer from the same problem: they show you the effect runtime's internals, rather than your business logic.
With PureLogic, your code executes as regular Scala code. Stack traces point to your functions. Profilers show you where time is actually spent. Debuggers step through your logic line by line. Exceptions created inside a PureLogic program have meaningful stack traces that you can read and act on.
When to use PureLogic
PureLogic is a good fit when:
- You have domain logic that can be expressed as pure functions with
Reader,Writer,State, andAbortcapabilities. - You want simple, readable code without monadic boilerplate.
- You care about performance and want to avoid the overhead of monads.
- You value testability and want to test your business logic in isolation.
PureLogic is not a replacement for effect systems like ZIO or Cats Effect. It does not manage asynchronous I/O, concurrency, or resource safety. It is designed for the pure core of your application, not the imperative shell.